プロジェクト内容
顧客様: NY拠点の投資ファンド. AUM 50 Billion USD (管理資産 6兆円以上)
概要: 2019年に新設されたオルタナティブ・データ・チーム(金融レポート・データ以外のデータを分析して投資情報を読み出す)の開発チームリーダー兼アーキテクトとして参画し、データプラットフォームの設計・開発・実装を行いました。2022年末現在も同ポジションにて、より高度なデータ分析プロジェクト等に関わっております。
結果: チーム発足後2か月で投資アナリスト達に有効な投資インサイトを与えるデータ分析環境の構築を達成しました。新しいデータベンダー、自社によるスクレイピングを数時間でデータパイプラインに乗せることが可能な継続的インテグレーションを実装し、2022年現在で250を超えるデータパイプラインを構築・運用しております。データ分析に関連したプロジェクトとして、機械学習を用いたデータの分類・KPI予測モデルの作成なども行っております。
サービス内容: 利用クラウドプラットフォームの選定から、コストパフォーマンスの良いサービスや実装方法の選定を行い、チームの社内での成功に貢献しました。
- クラウドプラットフォームの評価・選定
- 利用サービス/技術の評価・選定
- チームメンバーの採用活動
- データプラットフォームの構築・実装・運用
- データベンダーのデータ品質テスト
- データベンダーのデータの自動取得パイプラインの構築
- スクレイピングによる公開データの取得プラットフォーム
- クラウドサービス全体のコスト管理とモニタリングアプリケーションの実装
- 機械学習モデルの構築と、モデルを用いたデータ変換処理
- データをデータウェアハウスに自動ロードするパイプラインの構築
- データベンダーからのデータの自動ロード・アップデート処理
- パブリックデータのスクレイピング・データロード処理
実例
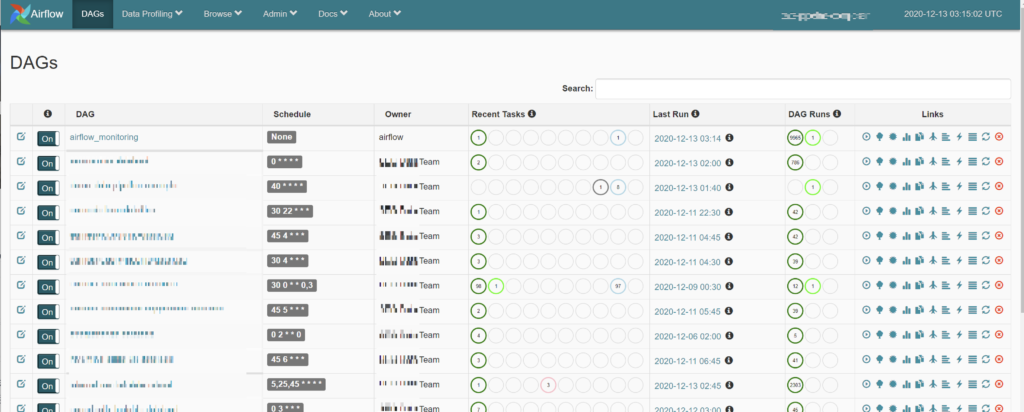
合計で100を超える(合計データサイズ 100TB以上)データベンダーからのデータ・自社スクレイプしたデータを決められた時間(毎時、毎日、毎週など)に取り込み、分析に活用しやすい形で処理し、データウェアハウス(BigQuery)にロードするデータパイプラインの構築・運用を、CloudComposer上で作成しました。新しいPipelineの追加・変更等も、CI/CDで容易に自動的に本番環境へリリースする設計になっており、新しいプロジェクトやベンダーのオンボーディングに対応できる設計になっております。
データパイプラインダッシュボード
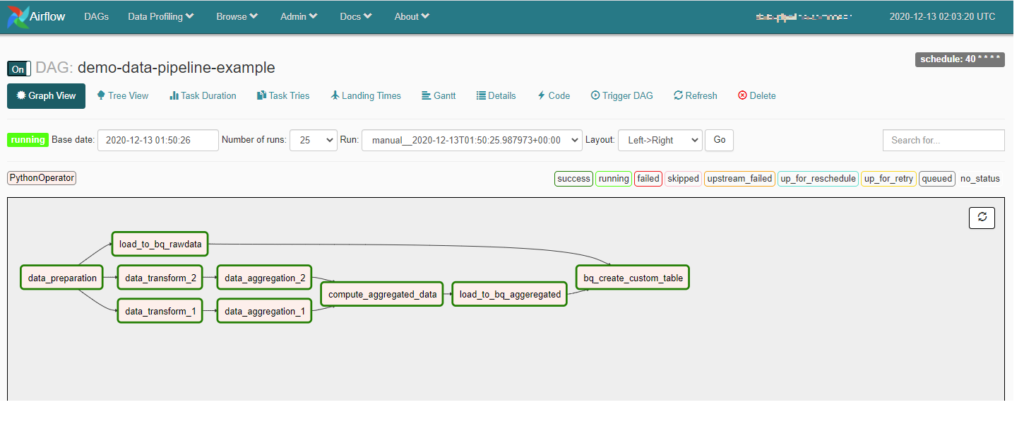
データパイプラインの一例
使用技術
- クラウドプラットフォーム – GCP (Google Cloud Platform)
- GKE (Google Kubernetes Engine)
- Cloud Composer2 (Airflow2)
- BigQuery
- Cloud Dataflow
- Artifact Registry
- Cloud Build (CI/CD) + GitHub
- Cloud Storage
- Cloud Firestore
- Compute Engine
- Cloud Functions
- Cloud Run
- Vertex AI
- データウェアハウス
- BigQuery
- Snowflake
- 主な使用言語:
- Python
- 機械学習ライブラリ:
- Tensorflow/Keras
- Scikit-Learn
- BI – ビジネスデータ分析ツール:
- Tableau